

TimechoDB V2.0.8 版本正式发布!
TimechoDB 是由 IoTDB 原厂团队开发的企业级时序数据库产品。V2.0.8 版本表模型新增 Object 数据类型,强化升级审计日志功能,优化树模型 OPC UA 协议,AINode 支持协变量预测与并发推理等功能,同时对数据库监控、性能、稳定性进行了全方位提升。
更多关于 V2.0.8 版本信息,欢迎联系我们获得企业版安装包。针对本版本主要核心功能,年后将有更详细的技术解析与直播讲解,敬请关注!
主要发布内容
查询模块:新增 DataNode 可用节点的列表展示,可查看节点的 RPC 地址和端口
查询模块:表模型新增统计查询耗时的系统表
存储模块:支持通过 SQL 查看创建表/视图的完整定义语句
存储模块:优化树模型 OPC UA 协议
系统模块:表模型新增 Object 数据类型
系统模块:强化升级审计日志功能
系统模块:表模型新增 DataNode 节点连接情况的系统表
AINode:内置 chronos-2 模型,支持协变量预测功能
流处理模块:创建全量同步 pipe 会自动拆分为实时、历史两个独立 pipe,可通过 show pipes 语句分别查看剩余事件数
其他:修复安全漏洞 CVE-2025-12183、CVE-2025-66566、CVE-2025-11226
...
本版本详细发布内容请查看天谋科技官网-发布历史页面:https://timecho.com/docs/zh/UserGuide/latest/IoTDB-Introduction/Release-history_timecho.html
功能详解:AINode 协变量预测功能
功能介绍
单变量预测:支持对单一目标变量进行预测。
协变量预测:可同时对多个目标变量进行联合预测,并支持在预测中引入协变量,以提升预测的准确性。
语法:
SELECT * FROM FORECAST(
MODEL_ID,
TARGETS, -- 获取目标变量的 SQL
[HISTORY_COVS, -- 字符串,用于获取历史协变量的 SQL
FUTURE_COVS, -- 字符串,用于获取未来协变量的 SQL
OUTPUT_START_TIME,
OUTPUT_LENGTH,
OUTPUT_INTERVAL,
TIMECOL,
PRESERVE_INPUT,
MODEL_OPTIONS]?
)语法说明:
model_id:必填,String 类型,预测所用模型的唯一标识。
targets:必填,通过 SQL 输入待预测目标变量的输入数据。
history_covs:通过 SQL 输入预测任务协变量的历史数据,用于辅助目标变量的预测。
future_covs:通过 SQL 输入预测任务协变量的未来数据,用于辅助目标变量的预测。
output_start_time:时间戳类型,输出的预测点的起始时间戳(起报时间)。
output_length:INT32 类型,输出窗口大小。
output_interval:时间间隔类型,输出的预测点之间的时间间隔。
timecol:String 类型,预测依据的时间列名。
preserve_input:Boolean 类型,输出结果集中是否保留目标变量输入的所有原始行。
model_options:String 类型,模型相关的 key-value 对。
使用举例
示例数据
创建数据库与源表,插入测试数据:
-- 1. 创建数据库
CREATE DATABASE testdb;
USE testdb;
-- 2. 创建源表
create table tab_real (
target1 DOUBLE FIELD,
target2 DOUBLE FIELD,
cov1 DOUBLE FIELD,
cov2 DOUBLE FIELD,
cov3 DOUBLE FIELD
);
-- 3. 插入测试数据
INSERT INTO tab_real (time, target1, target2, cov1, cov2, cov3) VALUES
(1, 1.0, 1.0, 1.0, 1.0, 1.0),
(2, 2.0, 2.0, 2.0, 2.0, 2.0),
(3, 3.0, 3.0, 3.0, 3.0, 3.0),
(4, 4.0, 4.0, 4.0, 4.0, 4.0),
(5, 5.0, 5.0, 5.0, 5.0, 5.0),
(6, 6.0, 6.0, 6.0, 6.0, 6.0),
(7, NULL, NULL, 7.0, NULL, NULL),
(8, NULL, NULL, 8.0, NULL, NULL);示例 1:使用历史协变量 cov1,cov2 和 cov3 辅助预测目标变量 target1 和 target2
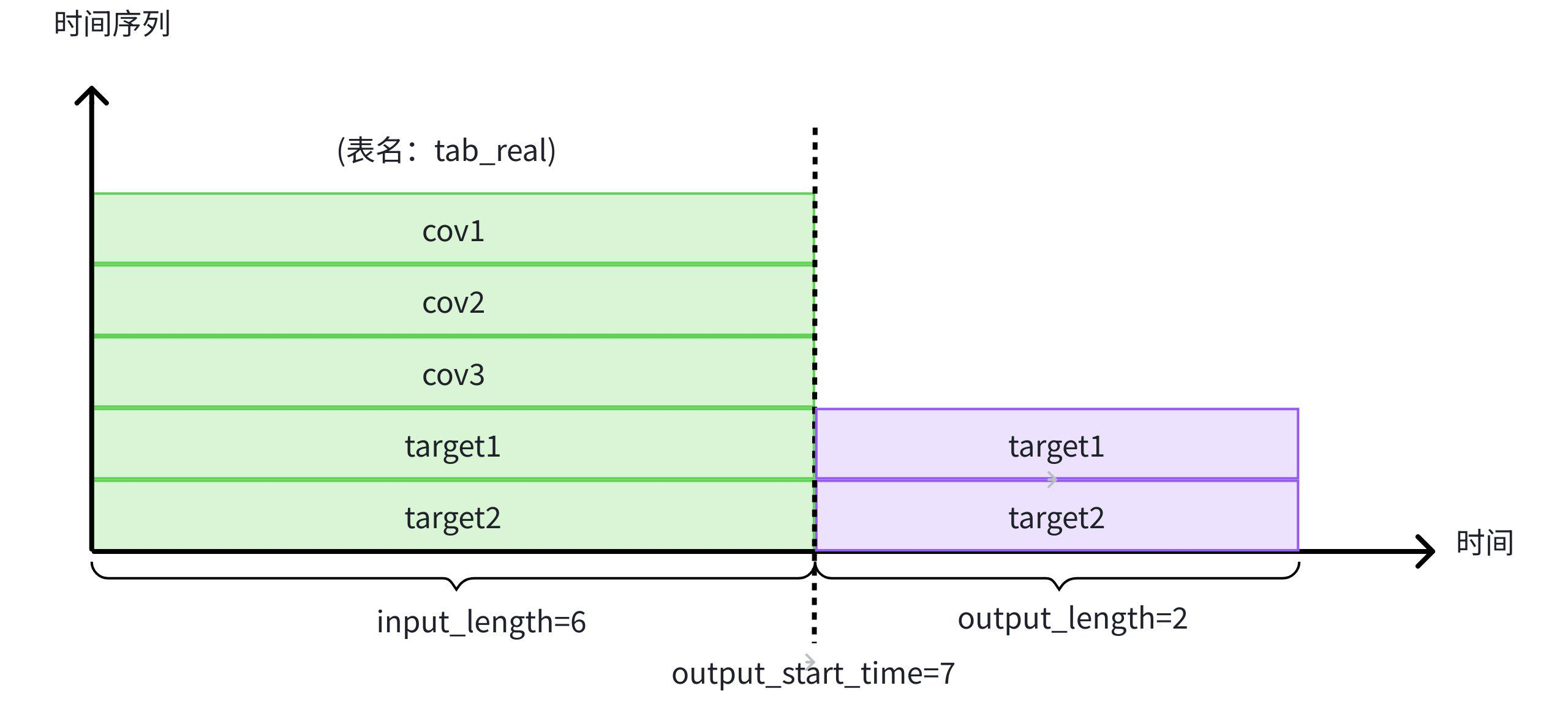
-- 使用表 tab_real 中 cov1,cov2,cov3,target1,target2 的前 6 行历史数据,预测目标变量 target1 和 target2 未来的 2 行数据
SELECT * FROM FORECAST (
MODEL_ID => 'chronos2',
TARGETS => (
SELECT TIME, target1, target2
FROM etth.tab_real
WHERE TIME < 7
ORDER BY TIME DESC
LIMIT 6) ORDER BY TIME,
HISTORY_COVS => '
SELECT TIME, cov1, cov2, cov3
FROM etth.tab_real
WHERE TIME < 7
ORDER BY TIME DESC
LIMIT 6',
OUTPUT_LENGTH => 2
)执行结果:
+-----------------------------+-----------------+-----------------+
| time| target1| target2|
+-----------------------------+-----------------+-----------------+
|1970-01-01T08:00:00.007+08:00|7.338330268859863|7.338330268859863|
|1970-01-01T08:00:00.008+08:00| 8.02529525756836| 8.02529525756836|
+-----------------------------+-----------------+-----------------+
Total line number = 2
It costs 0.315s示例 2:使用相同表中的已知协变量 cov1 和历史协变量 cov2,cov3 辅助预测目标变量 target1 和 target2
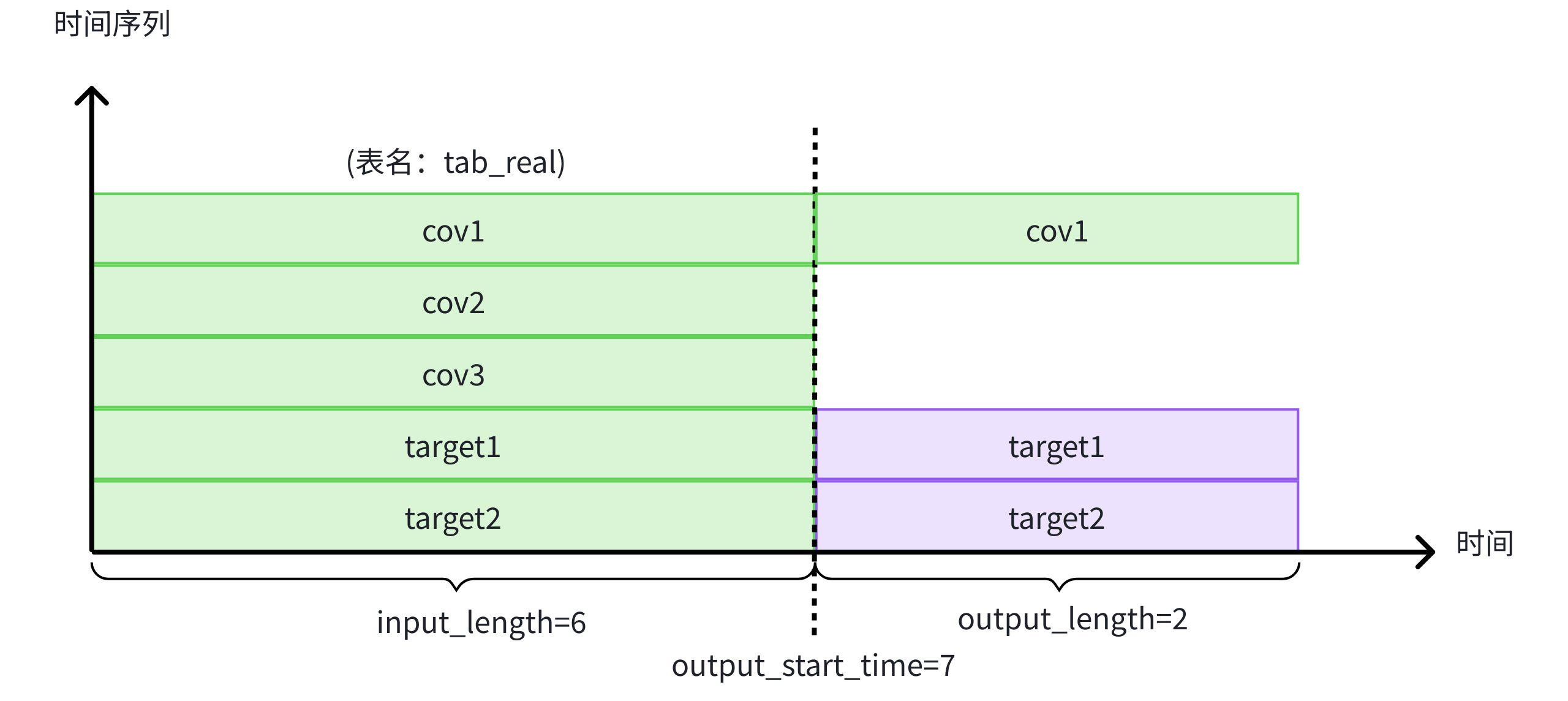
-- 使用表 tab_real 中 cov1,cov2,cov3,target1,target2 的前 6 行历史数据,以及同表中已知协变量 cov3 在未来的 2 行数据,来预测目标变量 target1 和 target2 未来的 2 行数据
SELECT * FROM FORECAST (
MODEL_ID => 'chronos2',
TARGETS => (
SELECT TIME, target1, target2
FROM etth.tab_real
WHERE TIME < 7
ORDER BY TIME DESC
LIMIT 6) ORDER BY TIME,
HISTORY_COVS => '
SELECT TIME, cov1, cov2, cov3
FROM etth.tab_real
WHERE TIME < 7
ORDER BY TIME DESC
LIMIT 6',
FUTURE_COVS => '
SELECT TIME, cov1
FROM etth.tab_real
WHERE TIME >= 7
LIMIT 2',
OUTPUT_LENGTH => 2
)执行结果:
+-----------------------------+-----------------+-----------------+
| time| target1| target2|
+-----------------------------+-----------------+-----------------+
|1970-01-01T08:00:00.007+08:00|7.244050025939941|7.244050025939941|
|1970-01-01T08:00:00.008+08:00|7.907227516174316|7.907227516174316|
+-----------------------------+-----------------+-----------------+
Total line number = 2
It costs 0.291s功能详解:表模型新增 Object 数据类型
功能介绍
Object 是新增的二进制数据类型,主要用于存储文档、音频、视频等较大的二进制文件,可实现非结构化文件与 IoTDB 时序数据的统一管理。
该类型与 BLOB 类型的区别为:查询 Object 列时,返回结果展示:(Object) XX.XX KB,真实 Object 数据存储路径为:${data_dir}/object_data,可通过 READ_OBJECT 函数读取其真实内容;而 BLOB 列查询时会直接返回完整的二进制原始内容。
注意:Object 类型本版本暂不支持树模型,表模型的数据同步、导入导出、数据写回等功能将在后续版本中适配。
基础功能
数据写入
语法:
insert into tableName(time, columnName) values(timeValue, to_object(isEOF, offset, content));参数说明:
isEOF:Boolean 类型,本次写入内容是否为 Object 的最后一部分
offset:INT64 类型,本次写入的内容在 Object 中的起始偏移量
content:十六进制(hex)格式,本次写入的 Object 内容
使用举例:
示例:向表 table1 中增加 Object 类型字段 s1,并写入总大小为 5 字节的 Object
ALTER TABLE table1 ADD COLUMN IF NOT EXISTS s1 OBJECT FIELD COMMENT 'object类型'不分段写入:
insert into table1(time, device_id, s1) values(now(), 'tag1', to_object(true, 0, X'696F746462'));分段写入:
--分段写入 Object 数据
--第一次写入:to_object(false, 0, X'696F')
insert into table1(time, device_id, s1) values(1, 'tag1', to_object(false, 0, X'696F'));
--第二次写入:to_object(false, 2, X'7464')
insert into table1(time, device_id, s1) values(1, 'tag1', to_object(false, 2, X'7464'));
--第三次写入:to_object(true, 4, X'62')
insert into table1(time, device_id, s1) values(1, 'tag1', to_object(true, 4, X'62'));数据查询
注意:
Object 类型不支持使用 GROUP BY、ORDER BY、OFFSET、LIMIT 子句。
Object 类型使用 FILL 子句只支持 PREVIOUS 的填充方式。
使用举例:
示例一:直接查询 Object 类型数据
select s1 from table1 where device_id = 'tag1'执行结果:
+------------+
| s1|
+------------+
|(Object) 5 B|
+------------+
Total line number = 1
It costs 0.428s示例二:通过 read_object 函数查询 Object 类型数据的真实内容
select read_object(s1) from table1 where device_id = 'tag1'执行结果:
+------------+
| _col0|
+------------+
|0x696f746462|
+------------+
Total line number = 1
It costs 0.188s更多内容推荐:
• 下载时序数据库 IoTDB 开源版
• 了解如何使用 时序数据库 IoTDB 企业版


